파이썬으로 웹 스크랩하기7/10
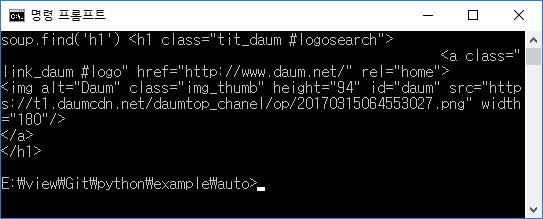
그러면 h1을 어떻게 찾아오는지 확인해보도록 하겠습니다.

위와같이 BeautifulSoup를 사용하여 h1 태그의 내용을 가져와 보겠습니다. 아래는 위의 결과를 가져온 화면입니다. 보이시나요?
daum의 h1은 이미지로 되어있으며 http://www.daum.net/ 으로 링크가 되어있는것을 확인할 수 있습니다.
위와같이 BeautifulSoup를 이용하면 웹페이지내에서 원하는 정보를 쉽게 가져올수 있습니다. 정규표현식등 별도로 파싱하는 작업을 하지 않아도 DOM 구조로 되어있는 문서는 모두 가져올수 있는것입니다.
이러한 BeautifulSoup은 파이썬 뿐만 아니라 다양한 언어로 만들어져 있으며 다른 언어를 이용하고 있다면 해당언어에서 어떻게 사용하는지 찾아서 이용한다면 쉽게 작업할 수 있습니다.
BeautifulSoup을 이용하여 웹페이지의 내용을 읽어오는 방법에 대해서 알아보았습니다. 이번에는 Selenium 라이브러리를 이용해서 웹페이지를 읽어와서 분석하는 방법에 대해서 알아보도록 하겠습니다.
selenium을 이용하여 할수 있는건 html을 가져와서 원하는 부분을 가져오는 작업을 할 수 있습니다. 그런데 이 작업 이외에도 웹페이지 snapshot을 만들수도 있습니다. 이부분에 대해서도 알아보도록 하겠습니다.