파이썬으로 웹 스크랩하기5/10
세번째는 Beautiful Soup을 이용해서 읽어온 html의 내용을 분석하는 방법에 대해서 알아보도록 하겠습니다.
html을 읽어오기 위해서는 DOM에 대해서 알아야 하는데요.
“문서 객체 모델(DOM; Document Object Model)은 객체 지향 모델로써 구조화된 문서를 표현하는 형식이다. DOM은 플랫폼/언어 중립적으로 구조화된 문서를 표현하는 W3C의 공식 표준이다. DOM은 또한 W3C가 표준화한 여러 개의 API의 기반이 된다.
DOM은 HTML 문서의 요소를 제어하기 위해 웹 브라우저에서 처음 지원되었다. DOM은 동적으로 문서의 내용, 구조, 스타일에 접근하고 변경하는 수단이었다. 브라우저 사이에 DOM 구현이 호환되지 않음에 따라, W3C에서 DOM 표준 규격을 작성하게 되었다.
DOM은 문서의 기반이 되는 데이터 구조에 제한을 두지 않는다. 잘 구조화된 문서는 DOM을 사용하여 트리 구조를 얻어낼 수 있다. 대부분의 XML 해석기와 XSL 처리기는 트리 구조의 이용에 대응해 개발되었다. 이 같은 구현에서는 문서의 전체 내용이 해석되어 메모리 저장되어야 한다. 때문에 DOM은 문서 요소가 임의적으로 접근되고 변경할 수 있어야 하는 응용 프로그램에 가장 적합하다. 한 번 해석 시 단 한 번의 선택적 읽기/쓰기가 이루어지는 XML 기반 응용 프로그램에서, DOM은 메모리에 상당한 부하를 가져온다. 이 경우처럼 속도와 효율적인 메모리 소비가 중요한 상황일 경우 SAX 모델이 장점을 가진다.”
위키백과에서는 위와 같이 설명하고 있습니다.
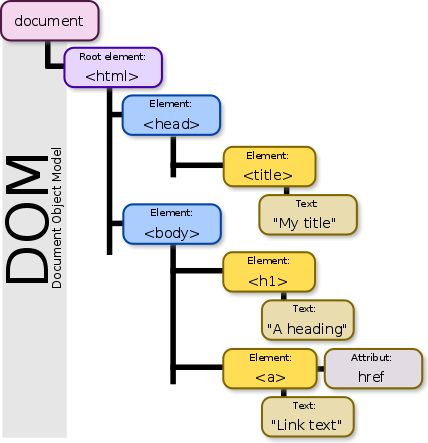
출처 : 위키백과
위와같이 하이라키 구조의 문서구조를 DOM이라고 합니다.
우리가 스크랩하기위한 웹페이지는 위와같은 DOM구조로 이루어져 있어서 이러한 구조를 잘 이해하는것은 웹페이지를 스크랩하는데 많은 도움이 될 것입니다.