자바를 이용하여 웹페이지 분석하기
1. 자바프로젝트 만들기
자바는 다양한 기능을 가지고 있습니다. 조금은 무겁고 다른 언어에 비해서 코딩량이 많지만 분명히 쓸만한 언어임에는 틀림없습니다.
파이썬 또는 Go등의 언어를 이용해서 웹페이지를 분석하는것은 어렵지 않습니다. 자바또한 jsoup을 이용하여 웹페이지를 분석하면 쉽게 분석할수 있습니다.
오늘은 자바를 이용하여 웹페이지를 읽어와서 원하는 정보를 가져오는 방법에 대해서 알아보돌고 하겠습니다.
우선 어떤페이지를 가져올지 확인해보도록 하겠습니다.
https://www.tiobe.com/tiobe-index/ 페이지에서는 언어순위를 제공하고 있습니다. 이러한 언어순위를 정보를 어떻게 가져오는지 확인해보도록 하겠습니다.
우선 자바에서 프로젝트를 만들어줍니다.
File > New > Java Project메뉴를 선택합니다.
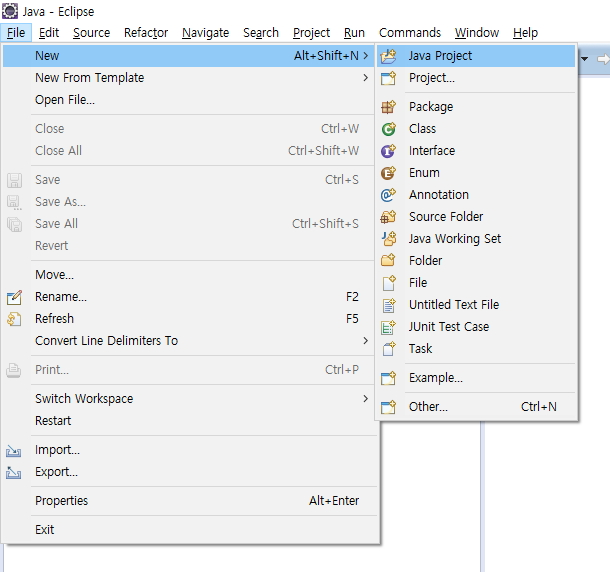

자바프로젝트에 Crawler을 입력하고 Finish 버튼을 클릭합니다.
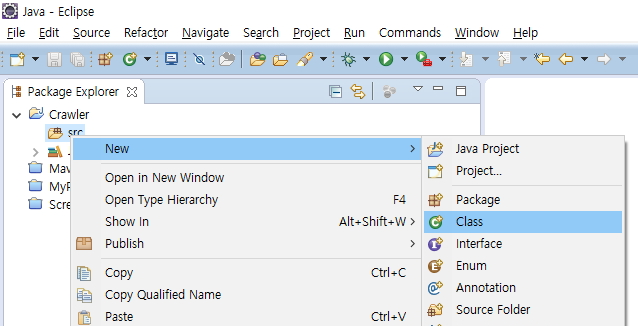
만들어진 프로젝트에서 src 폴더에서 마우스 오른쪽 버튼을 클릭합니다.

Package 이름에 common을 입력합니다.
Name 에 Crawler을 입력합니다.
public static void main(String[] args) 옵션을 체크합니다.
기본으로 main함수를 넣어주는지 확인하는 체크박스입니다. 선택하면 자동으로 main함수를 만들어주고 체크하지 않고 Finish버튼을 클릭하면 후에 소스에서 main 함수를 코딩해주면 됩니다.

Crawler.java파일이 생성되었습니다.
package는 common으로 설정되었습니다.
main함수가 기본으로 생성되었습니다.
2. jsoup설치하기
자바에서 웹페이지를 가져와서 분석하기 위해서는 jsoup 라이브러리를 이용해야 합니다. 파이썬에서 BeautifulSoup과 비슷한 역할을 하는 라이브러리 입니다.
jsoup 다운로드 : https://jsoup.org/download

현재 jsoup 버전은 1.10.3 버전이 최신버전입니다.
해당버전을 다운로드 받기 위해서 링크를 클릭합니다.
jsoup을 이클립스에서 사용하기 위해서는 다운로드 받은 파일을 이클립스 라이브러리에 추가해야 합니다.
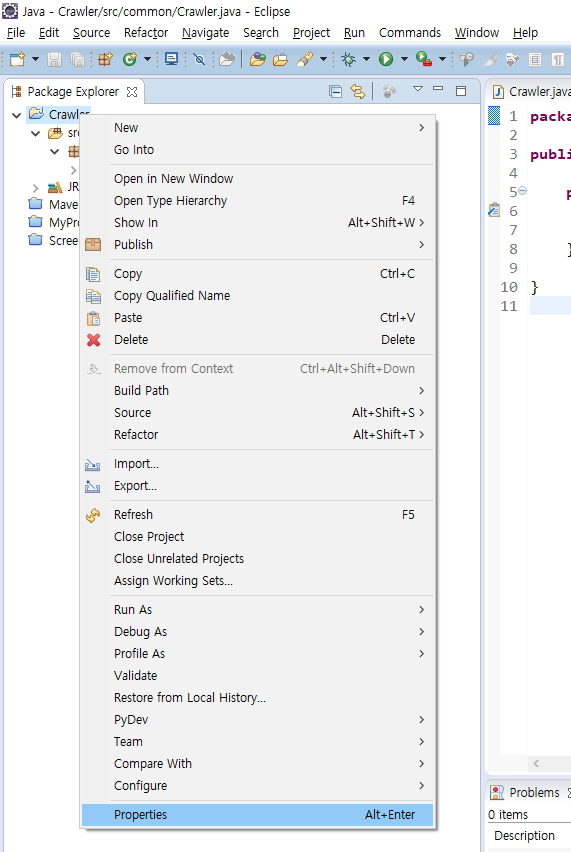
이클립스에서 프로젝트를 선택하고 마우스 우측버튼을 클릭합니다.
팝업메뉴에서 Properties를 선택합니다.
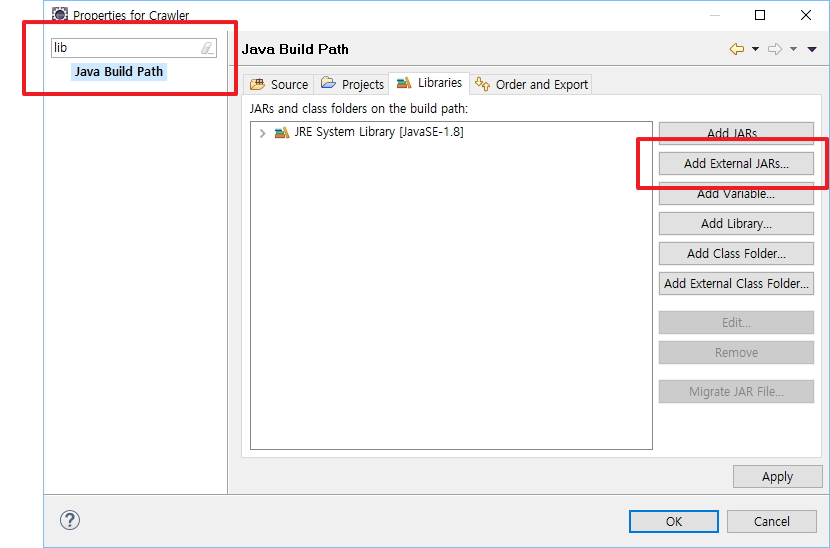
프로젝트 Properties 팝업창 좌측에 lib검색어를 입력하고 Java Build Path를 선택합니다.
오른쪽 Add Extenral JARs 버튼을 클릭해서 다운로드 받은 파일을 선택하고 확인 버튼을 클릭합니다. 이제 라이브러리는 정상적으로 추가되었습니다.
소스를 코딩하도록 하겠습니다.
getTIOBE 함수를 만들어 줍니다.
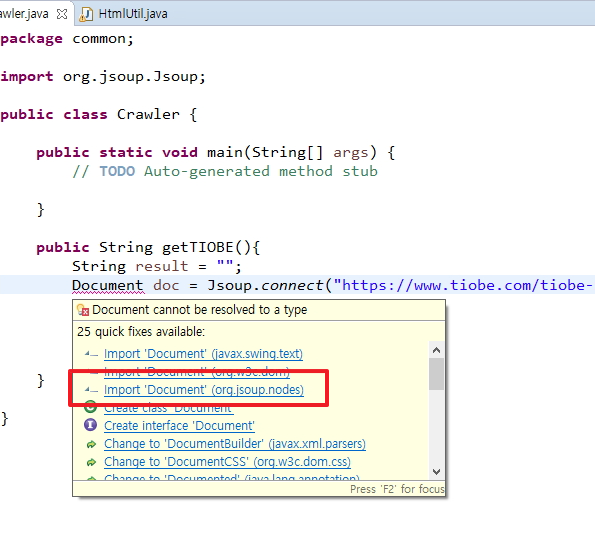
Document doc를 선언합니다.
선언하면 위와 같이 Document 에 붉은색 물결무늬가 생성됩니다. 마우스를 오버하면 Document cannot be resulted to a type으로 시작하는 창이 생성됩니다. 거기에서 import “Document” (org.jsoup.nodes)를 클릭합니다.
그러면 위쪽에 import org.jsoup.nodes.Document;가 자동으로 추가됩니다.
위 창은 자료형이 여러개인경우 하나를 선택하도록 도와주는것입니다.

정확한 import를 해주고 나면 Jsoup.connet 하단에 붉은 줄무늬가 생성됩니다. 이경우에도 마우스를 오버하면 어떤 작업을 해야할지 나타납니다. 이번엔느 jsoup의 connect 함수가 exception을 일으키는데 어떻게 처리할지에 대해서 선택하는 것입니다
Add throws declaration을 선택하면 함수에 throws IOException 코드가 자동으로 생성되고
Surround with try / catch를 선택하면 해당 블록을 감싸는 try / catch문의 코드가 자동으로 생성됩니다.
해당프로젝트의 코딩규칙에 맞춰서 선택하면 됩니다.
이제 jsoup을 이용해서 웹페이지를 가져오는 방법을 알아보았습니다. 그러면 이제 해당 웹페이지에서 원하는 부분을 어떻게 가져오는지 확인해보도록 하겠습니다.
크롬에서 https://www.tiobe.com/tiobe-index/ 주소를 입력하고 엔터키를 클릭합니다.
페이지가 모두 로드되었으면 F12버튼을 눌러줍니다.
그러면 아래와 같이 좌측에 소스 우측에 Html이 출력될 것입니다.

우리가 읽어 오고 싶은 부분은 Ranking 20의 리스트를 나타내는 부분입니다. 해당 부분을 선택하면 우측에 해당부분의 첫 부분이 나타납니다.
<table class=”table table-striped table-top20″>
위와 같은 부분이 나타나는데요. class이름이 세개가 있습니다.
table, table-striped, table-top20 이렇게 세개가 있는데 이 세개중에 table-top20이 이 테이블의 유일한 class이름 일거 같습니다. 그럼 이 이름을 가지고 내용을 찾아보도록 하겠습니다.

Jsoup.connect를 통해서 가져온 doc에 select함수를 이용해서 값을 가져오도록 하겠습니다.
doc.select(“.table-top20”)
class를 사용할때는 “.”을 사용합니다. id를 사용할때는 “#”을 사용합니다. html 태그를 사용할 때는 그냥 이름을 입력하면 됩니다.
여기서는 위에서 class이름으로 되어있었기 때문에 .table-top20을 query이름으로 넣었습니다.

select 쿼리에 .table-top20을 입력하고 값을 가져왔습니다.
el.size()로 확인하니 1개의 값을 가져왔습니다.
el.text() <- 해당 내용의 값을 html값을 제거한 텍스트 내용을 가져옵니다.
el.html() <- 해당 내용읠 값을 html로 가져옵니다.
el.size()를 가져온다는 것은 el은 List라는 뜻입니다. 그러면 한개인경우와 여러개인경우 어떻게 값을 가져와야 할까요?
아래에서 이부분을 알아보도록 하겠습니다.

코드를 조금 수정했습니다. 한개의 값을 리턴한 경우와 한개 이상의 값을 리턴한 경우입니다.
한개는 그냥 html 또는 text를 가져오면 됩니다.
그런데 한개 이상에서는 for 문을 돌면서 여러개의 값을 가져옵니다.
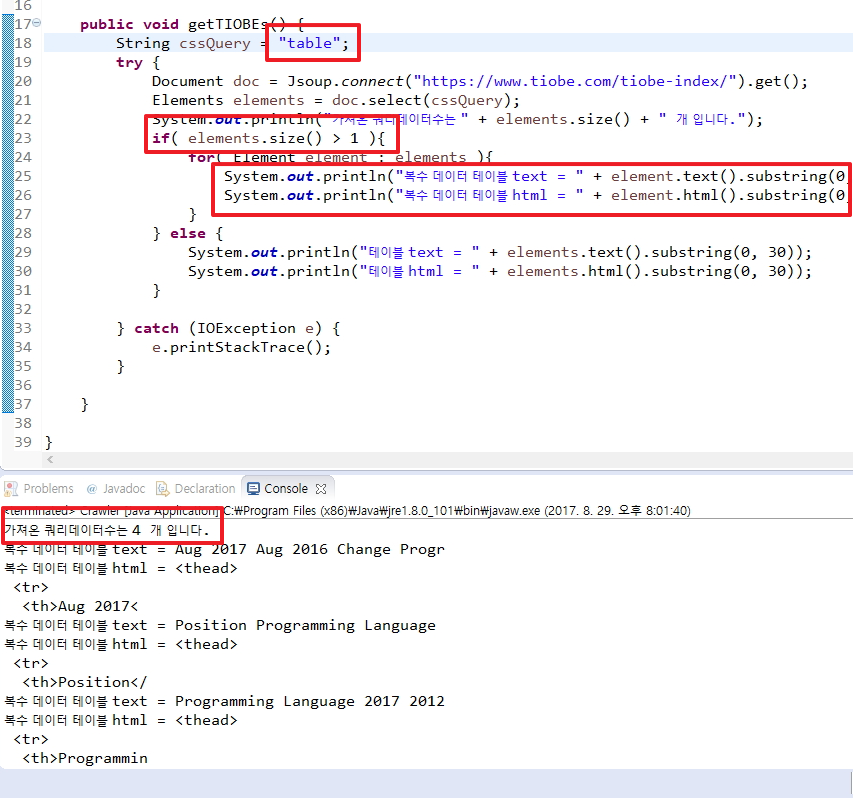
이번에는 쿼리에 table을 넣어보도록 하겠습니다. table만 넣은경우 해당 화면에서는 테이블의 갯수가 4개인것을 확인할수 있습니다.
이런경우 for문을 돌면서 4개의 html과 text의 내용을 모두 가져왔습니다.

프로그램을 실행시키는 방법은 소스창에서 마우스 오른쪽을 클릭하고 Run As > Java Application을 선택하면 소스가 실행됩니다.
이상과 같이 jsoup을 이용해서 웹페이지를 읽어오고 원하는 위치의 내용을 가져오는 방법을 알아보았습니다.
소스는 아래에서 다운받으시면 됩니다.
http://w3devlabs.net/wp/?attachment_id=16945
다운받은후에 확장자를 java로 변경하면 됩니다.